存储网络论文:
- From Luna to Solar: The Evolutions of the Compute-to-Storage Networks in Alibaba Cloud
- When Cloud Storage Meets RDMA
- X-RDMA: Effective RDMA Middleware in Large-scale Production Environments
存储网络论文:
ef_vi允许应用程序直接访问Solarflare网卡数据路径,以降低延迟并减少每条消息的处理开销。它可以直接用于那些需要最低延迟的发送和接收API,并且不需要POSIX套接字接口的应用程序。
ef_vi的主要特点是:
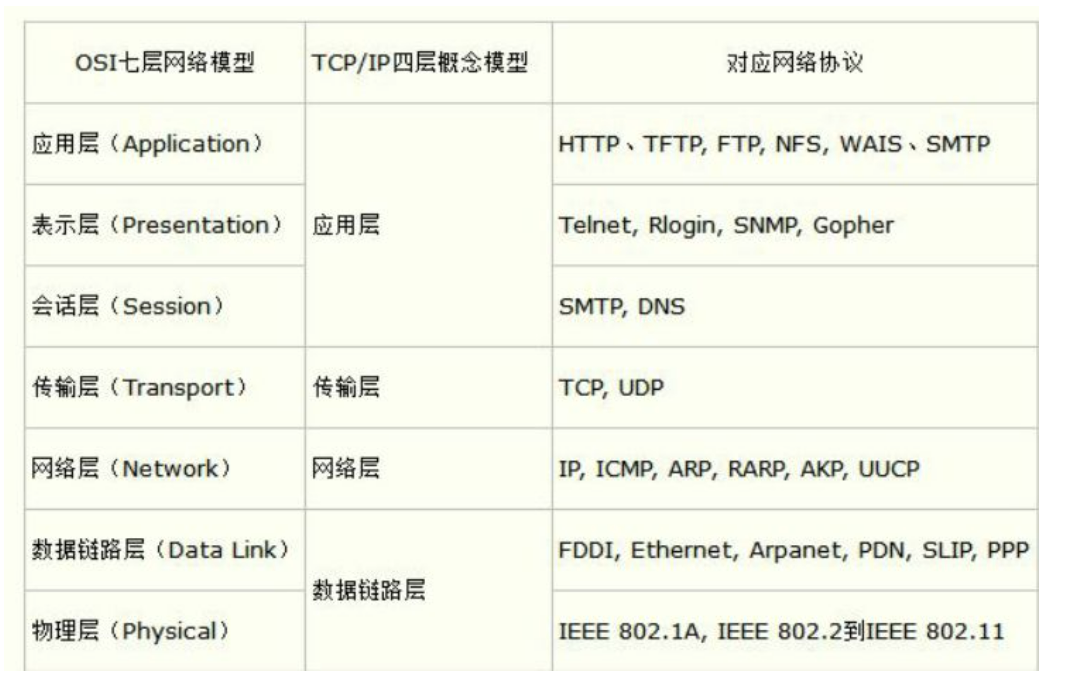
ef_vi位于数据链路层,OSI第二层,用来收发以太网数据帧。本质上是网络适配器提供的VNIC(虚拟网络接口控制器)接口的封装。
ef_vi可以用来指定只处理某个端口的数据包,也就是可以与标准linux内核网络栈和其他加速技术同时使用。
可用于替代socketsAPI。
例如:在hft系统中处理多播UDP数据报。
应用程序将建立一个ef_vi实例
应用程序给定目标IP地址和端口号。
只有需要加速的数据包才由ef_vi处理。
其他还是内核处理。
应用程序可以创建多个ef_vi实例来处理不同的数据包流,或者在多个线程上分散负载。如果每个传输线程都有自己的ef_vi实例,那么它们可以在无锁和不共享状态的情况下并发传输数据包。这大大提高了效率。 啥意思?可以多线程处理同一条数据路径?
Solarflare的SolarCapture软件构建在ef_vi API之上。与传统的捕获API一样,ef_vi可用于捕获到达网络端口或子集的所有数据包,并打时间戳。
其他用途:包重放、作为end-station、网络虚拟化。
每个ef_vi实例,提供了一个网卡的虚拟接口,如下:
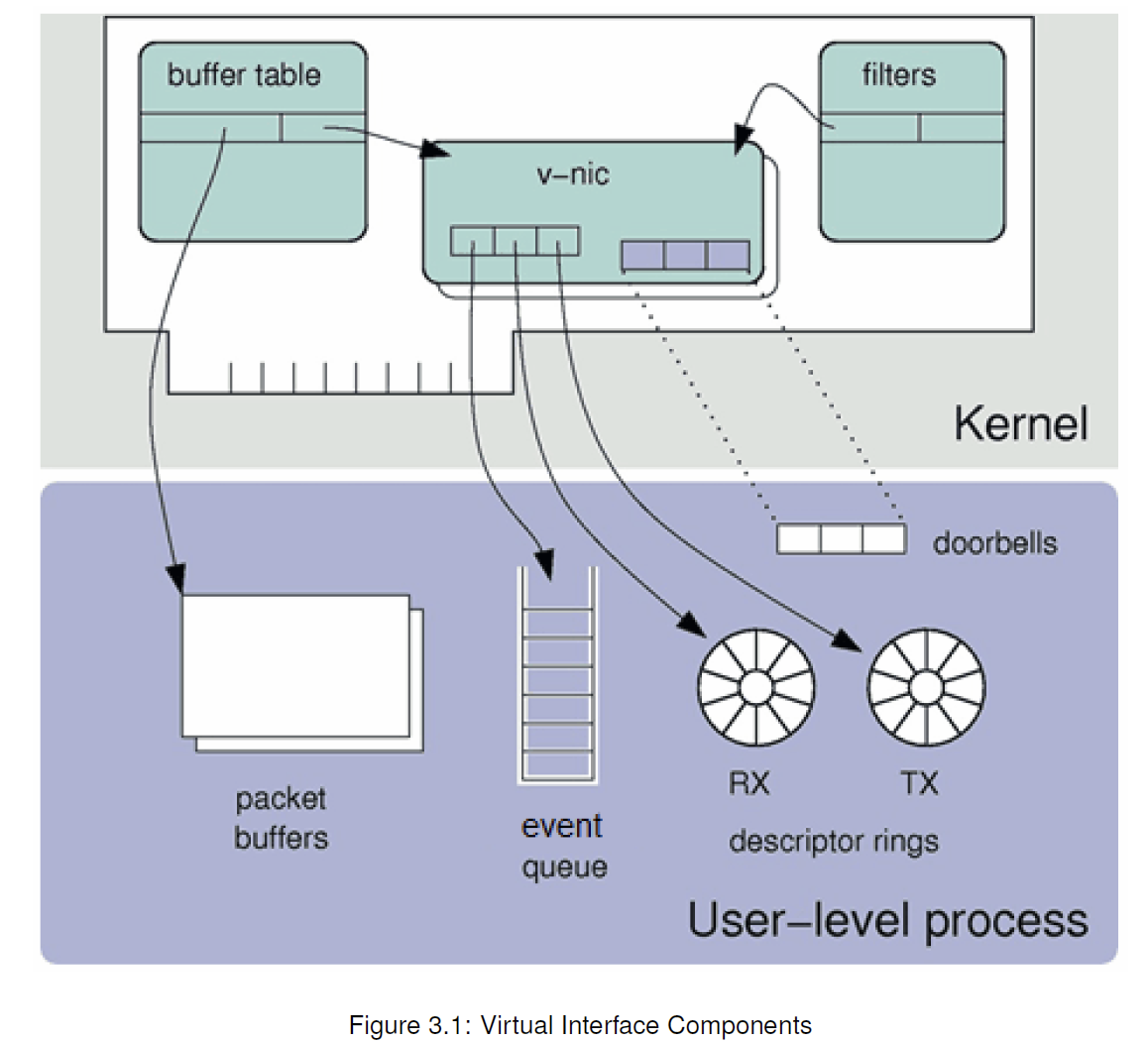
一个虚拟接口包括三个组件:Event queue、Transmit descriptor ring、Receive descriptor ring。(这是软件资源)
一个虚拟接口(就是一个ef_vi实例)的硬件资源:
两个寄存器,用来通知TX、RX 缓冲区可用。?
一些定时器?
一个共享的中断。
用来网卡和应用程序之间传递消息。比如通知应用程序有数据包到达的事件。
将数据包从应用程序传递到网卡。环中的每个条目都是一个描述符,它引用包含数据包的缓冲区。每个数据包由一个或多个描述符描述。
数据包的传输在后台进行,适配器在数据包传输完成后通过事件队列通知应用程序。
将数据包从适配器传递到应用程序。应用程序必须预先分配缓冲区并将其发送到接收描述符环。环中的每个条目都是一个描述符,它引用适配器可以将数据包放入的“空闲”缓冲区。
当适配器向ef_vi实例发送数据包时,它会将数据包复制到下一个可用的接收缓冲区,并通过事件队列通知应用程序。
大数据包可以分散在多个接收缓冲区上。
发送或接收缓冲区的内存区域要使用ef_memreg接口注册。
这确保了内存区域符合ef_vi的要求:
就是收发数据包的buffer,通常大小2kb,只有同一保护域中的虚拟接口才能访问。是memory region么。
大数据包可能分散在多个packet buffer上。
每个包缓冲区用一个descriptor引用,包含了:
rings上存放的就是这些描述符。
?没看懂
选择哪些数据包被传递到虚拟接口。其他的走内核。
根据数据包的特征过滤。比如以太网MAC地址、VLAN标记、IP地址和端口号。
ef_vi用到的硬件资源怎么理解。
BAOVerlay将overlay文件看做一系列块,通过块,baoverlay实现了非阻塞的写实拷贝机制,每次要写入时,并不是完整的文件从下层到上层进行拷贝,而是需要更新的块从下层到上层异步复制。最后,baoverlay实现了一种新的文件格式B-Cow,用来紧凑存储overlay文件用来节省存储空间。分配存储空间被推迟,知道实际实际更新了overlay文件的块。
在POSIX兼容的文件系统中,文件或目录与inode数据结构关联,inode存储了文件的元信息,例如文件的所有权、访问模式和磁盘中的数据位置,该文件的操作。overlay文件系统为每个
overlay2的open函数会创建一个关联到overlay文件的 inode,并填充所需要的信息。其中一个主要的步骤就是找出关联的underlaying文件属于哪一层,从而根据backing fs的inode 的fetch操作,然后将其放入overlay inode的一个字段中。
对于 Docker 等大多数 Linux 容器来说,Cgroups 是用来制造约束的主要手段,而 Namespace 技术则是用来修改进程视图的主要方法。
namespace是linux内核支持的特性,来实现进程资源隔离。
创建新进程fork时,底层调用clone函数,通过设置参数实现。
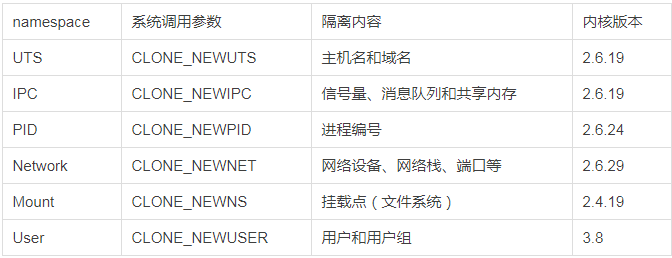
比如一个骨干程序,对clone可以传入不同的参数达到不同的namespace隔离:
1 | #define _GNU_SOURCE |
clone可以选择传入不同的参数,比如:
1 | int container_pid = clone(container_main, container_stack + STACK_SIZE, SIGCHLD | CLONE_NEWUTS | CLONE_NEWIPC | CLONE_NEWPID, NULL); |
ipc隔离可s以通过ipcmk和ipcs命令验证
从内核实现角度,task_struct里有一个指向namespace的指针nsproxy
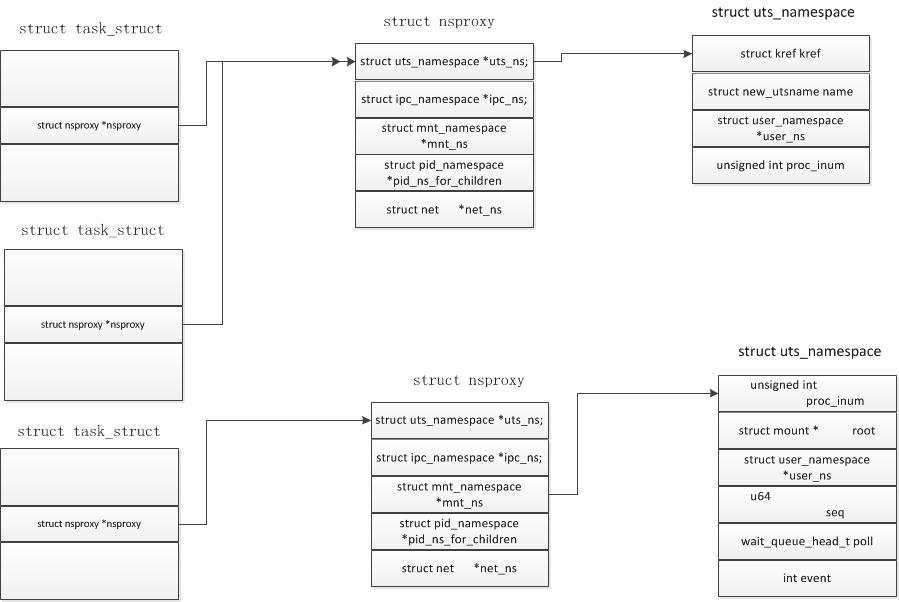
clone时候:
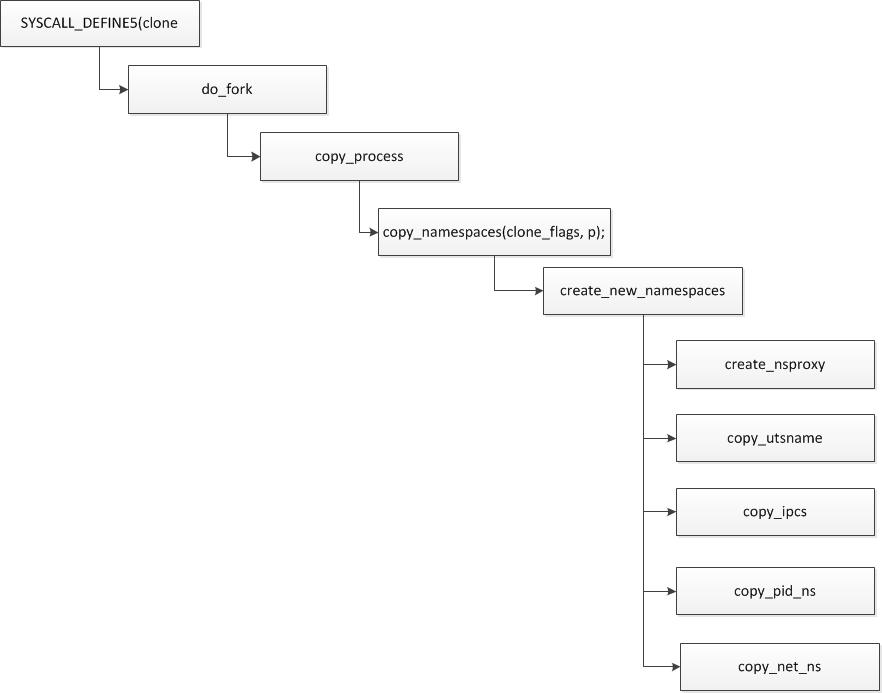
在task_struct里有一个字段:
1 | #ifdef CONFIG_CGROUPS |
里面包含了一个css_set结构体,里面存储了与进程相关的cgroups信息。
cg_list是一个链表,链接到同一个css_group的进程被组织成一个链表。
1 | struct css_set { |
Update your browser to view this website correctly. Update my browser now